
Custom GPT Actions let us expose an API that ChatGPT calls on behalf of users. We build the backend — ChatGPT handles the frontend: web, mobile, voice, message history, auth.
But a production-grade RAG backend needs more than basic vector search. This article covers building a high-performance Custom GPT in Go, along with the interesting parts: hybrid search with Reciprocal Rank Fusion, chunk stitching for contiguous context, query-focused summarization with SLMs, and decoupled embedding strategies for A/B testing.
We’ll use two Go frameworks:
- go-api-boot: DI, ODM with vector/text search, multiple embedding providers
- agent-boot: Tool output formatting with optional LLM summarization
Architecture
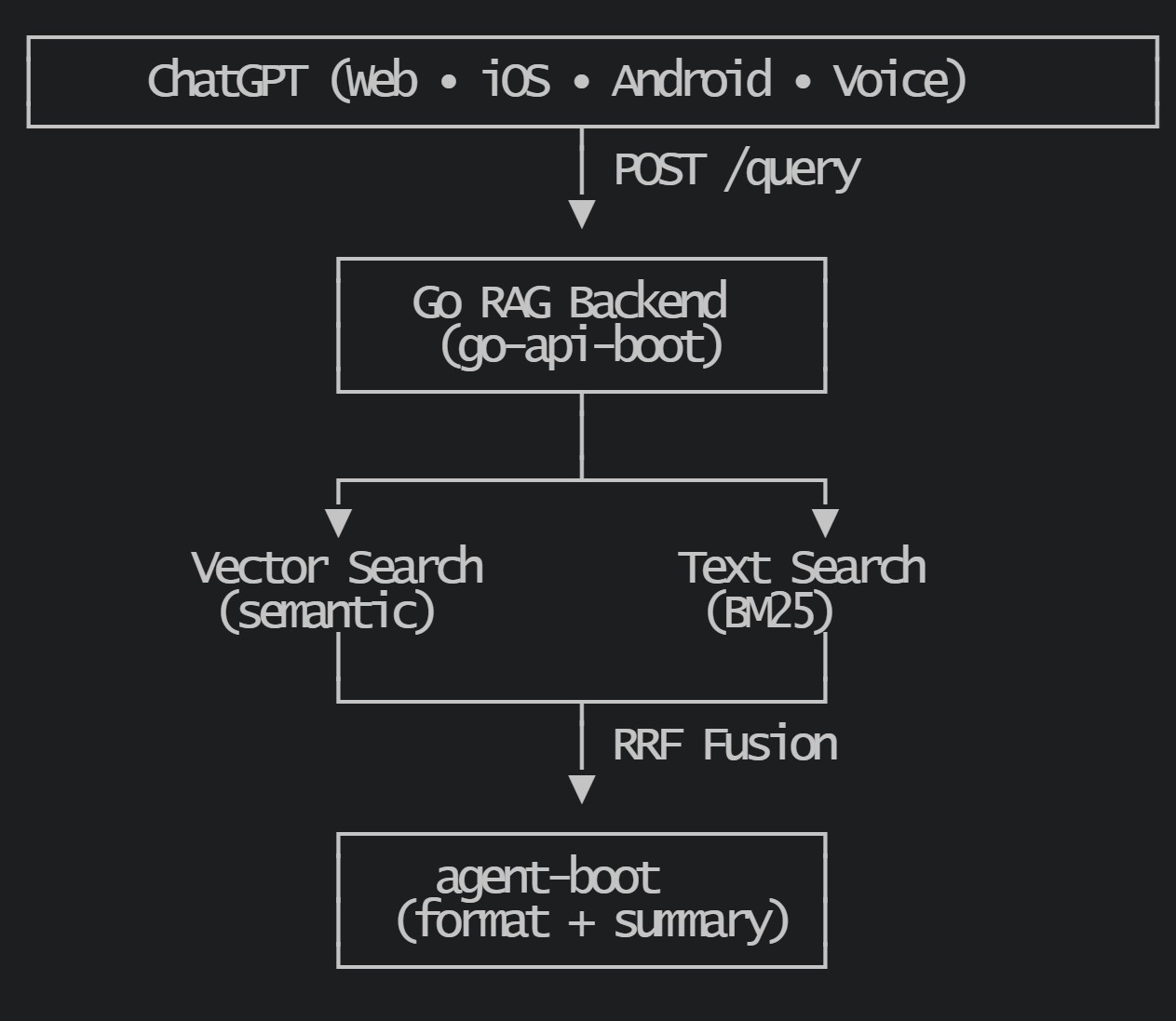
The Interesting Parts
1. Hybrid Search with Reciprocal Rank Fusion
Neither vector nor text search alone is sufficient. Vector search captures semantics but misses exact keywords. Text search finds exact matches but misses related concepts.
The naive solution — normalizing scores and averaging — is fragile. BM25 scores range 0-1000+, cosine similarity is -1 to 1, and both drift when you rebuild indexes or swap embedding models.
RRF uses rank instead of score. The formula: score(d) = Σ weight / (k + rank)
const rrfK = 60 // from the original RRF paper
func (s *SearchTool) hybridSearch(ctx context.Context, query string) []*ChunkModel {
// Fire both searches in parallel
textTask := s.chunkRepository.TermSearch(ctx, query, odm.TermSearchParams{
IndexName: db.TextSearchIndexName,
Path: db.TextSearchPaths,
Limit: 20,
})
embedding, _ := s.embedder.GetEmbedding(ctx, query, embed.WithTask("retrieval.query"))
vecTask := s.vectorRepository.VectorSearch(ctx, embedding, odm.VectorSearchParams{
IndexName: db.VectorIndexName,
Path: db.VectorPath,
K: 20,
NumCandidates: 100,
})
// Collect ranks from each engine
textRanks, cache := collectTextSearchRanks(textTask)
vecRanks := collectVectorSearchRanks(vecTask)
// RRF: rank-based fusion
combined := make(map[string]float64)
for id, r := range textRanks {
combined[id] = 1.0 / float64(rrfK+r)
}
for id, r := range vecRanks {
combined[id] += 1.0 / float64(rrfK+r)
}
// Keep top-N with min-heap
h := ds.NewMinHeap(func(a, b pair) bool { return a.score < b.score })
for id, sc := range combined {
h.Push(pair{id, sc})
if h.Len() > maxChunks {
h.Pop()
}
}
return s.fetchChunksByIds(ctx, cache, h.ToSortedSlice())
}
Rank #1 gets 1/61 ≈ 0.016. Rank #20 gets 1/80 = 0.0125. A document appearing high in both lists accumulates significantly more weight than one appearing only in the tail of one list.
Ref: Search Tool Implementation
2. Chunk Stitching: From Fragments to Coherent Context
Retrieved chunks rarely stand alone. A chunk might contain “…continuing the treatment protocol described above” — useless without its predecessor. Naive RAG systems return fragmented, incoherent passages.
Our solution: each chunk stores PrevChunkID and NextChunkID. After hybrid search ranks chunks, we stitch them with their neighbors:
// For each retrieved chunk, collect its neighbors
for _, ch := range sectionChunks {
if id := ch.PrevChunkID; id != "" && !added.Contains(id) {
added.Add(id)
needIds = append(needIds, id)
}
if id := ch.ChunkID; id != "" && !added.Contains(id) {
added.Add(id)
needIds = append(needIds, id)
}
if id := ch.NextChunkID; id != "" && !added.Contains(id) {
added.Add(id)
needIds = append(needIds, id)
}
}
// Fetch all neighbors in one DB round-trip
allChunks := s.fetchChunksByIds(ctx, cache, needIds)
// Join sentences from contiguous chunks
sentences := make([]string, 0, len(allChunks)*20)
for _, chunk := range allChunks {
sentences = append(sentences, chunk.Sentences...)
}
The result: if chunk N is retrieved, chunks N-1 and N+1 are automatically included. Consecutive retrieved chunks (N, N+1, N+2) merge into a single contiguous passage. The LLM sees coherent text, not sentence fragments.
This is grouped by SectionID — chunks from the same document section are combined, sorted by WindowIndex, and emitted as a single ToolResultChunk with full context.
Why Chunk Stitching? This chunking strategy becomes particularly crucial for documents with poor hierarchical structure or sections that exceed natural semantic boundaries. While documents with good hierarchy and clear section divisions may not require this approach, it has been tested extensively on large, unstructured documents with sections exceeding 800 words. The process involves breaking sections at sentence boundaries, then creating sliding windows of 700 tokens per chunk. To maintain semantic continuity, each chunk includes a small overlap with its predecessor during the embedding process, ensuring context preservation across chunk boundaries.
Ref: Chunk Stitching Implementation
3. Query-Focused Summarization with SLM & Rendering
Raw retrieved passages often contain noise — tangential details, boilerplate, context that doesn’t address the query. Dumping everything into the final LLM wastes tokens and dilutes attention.
The solution: summarize each passage with respect to the query using a small, fast model (SLM) before the final LLM generates the answer.

This two-stage approach focuses attention. The SLM extracts query-relevant content from each passage; the final LLM (ChatGPT in our case) reasons over clean, focused context.
agent-boot’s ToolResultRenderer handles this:
// Configure with a fast SLM for summarization
llmClient := llm.NewAnthropicClient("claude-3-5-haiku-20241022")
renderer := agentboot.NewToolResultRenderer(
agentboot.WithSummarizationModel(llmClient),
)
Ref: Using Tool Result Renderer
The renderer summarizes each chunk with respect to the query and formats results as Markdown. Why Markdown over JSON? JSON is verbose, consumes more tokens, and a cluttered JSON context can overwhelm the LLM — leading to hallucinations or missed details. agent-boot’s ToolResultRenderer formats results to Markdown by default.
toolResultChunks, err := linq.Pipe4(
linq.NewStream(linqCtx, toolResultChan, cancel, 10),
linq.SelectPar(func(raw *schema.ToolResultChunk) *schema.ToolResultChunk {
if summarizeResult {
return r.summarizeResult(linqCtx, raw, query, toolInputsMD)
}
// If summarization is not enabled, return the raw result
return raw
}),
linq.Where(func(chunk *schema.ToolResultChunk) bool {
// Filter out nil results and those marked as irrelevant
if chunk == nil {
return false
}
return true
}),
linq.Select(func(chunk *schema.ToolResultChunk) string {
r.reporter.Send(NewToolExecutionResult(r.toolName, chunk))
s := formatToolResultToMD(chunk)
return string(s)
}),
linq.ToSlice[string](),
)
Ref: Tool Result Renderer Implementation
Supporting Framework: go-api-boot
1. Dependency Injection Without the Ceremony
Most Go DI solutions feel like Java. go-api-boot takes a different approach — provider functions that declare their dependencies through function signatures:
func main() {
dotenv.LoadEnv()
boot, _ := server.New().
GRPCPort(":50051").
HTTPPort(":8081").
ProvideFunc(odm.ProvideMongoClient). // reads MONGO_URI
ProvideFunc(embed.ProvideJinaAIEmbeddingClient). // reads JINA_API_KEY
AddRestController(controller.ProvideQueryController).
Build()
boot.Serve(getCancellableContext())
}
The magic is in AddRestController. Our controller declares what it needs:
func ProvideQueryController(
mongo odm.MongoClient,
embedder embed.Embedder,
) *QueryController {
// Both dependencies resolved automatically
}
The framework builds a dependency graph and resolves it at startup. No Resolve calls scattered through your code, no interface registrations, no reflection magic at runtime.
2. Self-Describing DB Models with Auto-Indexed Collections
DB Models declare their own index specifications. The ODM creates them on startup if missing:
type ChunkAnnModel struct {
ChunkID string `bson:"_id"`
Embedding bson.Vector `bson:"embedding"`
}
func (m ChunkAnnModel) VectorIndexSpecs() []odm.VectorIndexSpec {
return []odm.VectorIndexSpec{{
Name: "chunkEmbeddingIndex",
Path: "embedding",
NumDimensions: 2048,
Similarity: "cosine",
Quantization: "scalar",
}}
}
type ChunkModel struct {
ChunkID string `bson:"_id"`
Title string `bson:"title"`
Sentences []string `bson:"sentences"`
// ...
}
func (m ChunkModel) TermSearchIndexSpecs() []odm.TermSearchIndexSpec {
return []odm.TermSearchIndexSpec{{
Name: "chunkIndex",
Paths: []string{"sentences", "sectionPath", "tags", "title"},
}}
}
Separating ChunkModel (content + metadata) from ChunkAnnModel (embeddings) decouples the embedding strategy from the data. You can experiment with different embedding models — different dimensions, providers (Jina, Gemini, etc.), or fine-tuned variants — each in its own collection, without touching the source content.
Benefits this pattern provides:
- Swap embedding models without migrating content
- Run A/B tests with different embeddings in parallel
- Smaller vector index (just ID + vector, not all metadata)
- Re-embed incrementally when upgrading models
go-api-boot’s ODM makes this even more flexible — CollectionName() is a method, not a constant. One can return different collection names based on runtime conditions:
func (m ChunkAnnModel) CollectionName() string {
if featureFlags.UseNewEmbeddings {
return "chunk_ann_gemma"
}
return "chunk_ann_jina_v2"
}
Or parameterize it via request context — pass an embedding model identifier in the URL, and your Custom GPT serves results from different vector collections without code changes. A/B test embedding models in production by simply changing a query parameter.
Type-safe repositories can be instantiated in one line:
chunkRepo := odm.CollectionOf[db.ChunkModel](mongo, "mydb")
vectorRepo := odm.CollectionOf[db.ChunkAnnModel](mongo, "mydb")
Both VectorSearch and TermSearch return channels for parallel execution.
Ref:
3. Wiring Routes
Controllers implement a Routes() method:
func (c *QueryController) Routes() []server.Route {
return []server.Route{
{
Pattern: "/query",
Method: http.MethodPost,
Handler: APIKeyAuthMiddleware(c.HandleQuery),
},
{
Pattern: "/privacy-policy",
Method: http.MethodGet,
Handler: c.HandlePrivacyPolicy,
},
}
}
Ref: Query Controller Implementation
Exposing via Custom GPT Actions
One deployment option is Custom GPT Actions — ChatGPT calls your API on behalf of users, handling the entire conversational frontend.
Create an OpenAPI schema for your /query endpoint:
{
"openapi": "3.1.0",
"info": {
"title": "Knowledge Base API",
"version": "v1.0.0",
"x-privacy-policy-url": "https://your-api.com/privacy-policy"
},
"paths": {
"/query": {
"post": {
"operationId": "SearchKnowledgeBase",
"security": [{ "ApiKeyAuth": [] }],
"requestBody": {
"content": {
"application/json": {
"schema": { "$ref": "#/components/schemas/QueryRequest" }
}
}
}
}
}
},
"components": {
"securitySchemes": {
"ApiKeyAuth": { "type": "apiKey", "in": "header", "name": "X-API-Key" }
}
}
}
In ChatGPT’s GPT editor:
- Create new GPT → Configure → Create new action
- Paste your OpenAPI schema
- Add API key under Authentication (Custom header)
- Write instructions telling the GPT when/how to use your action
Done. Your backend is now a ChatGPT skill.
Deployment
Standard multi-stage Dockerfile, builds to ~10MB scratch image:
FROM golang:1.24-alpine AS builder
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY . .
RUN CGO_ENABLED=0 go build -ldflags="-s -w" -trimpath -o /app/api .
FROM scratch
COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/
COPY --from=builder /app/api /api
ENTRYPOINT ["/api"]
Deploy anywhere: Cloud Run, App Runner, Container Apps, Fly.io.
Key Takeaways
go-api-boot eliminates infrastructure boilerplate:
- DI through function signatures, resolved at startup
- ODM with self-describing indexes (vector + text search)
- Multiple embedding providers (Jina, OpenAI, etc.)
- Dynamic collection routing for A/B testing embeddings
Hybrid search with RRF outperforms either vector or text search alone:
- Rank-based fusion is stable across model/index changes
- No fragile score normalization
- Top ranks get disproportionate weight
Chunk stitching creates coherent context:
PrevChunkID/NextChunkIDlinks enable neighbor fetching- Consecutive chunks merge into contiguous passages
- LLMs see complete text, not fragments
Query-focused summarization with SLMs:
- Fast model (Haiku) summarizes each passage w.r.t. query
- Final LLM receives focused context, not raw dumps
- Improves answer quality while reducing token costs
agent-boot handles tool output formatting:
- Standard
ToolResultChunkschema - Markdown formatting (LLMs prefer it over JSON)
- Channel-based streaming
The pattern — building backends that LLMs call rather than frontends that call LLMs — is increasingly relevant as AI interfaces mature.
Resources
Follow for more Go + AI content.